

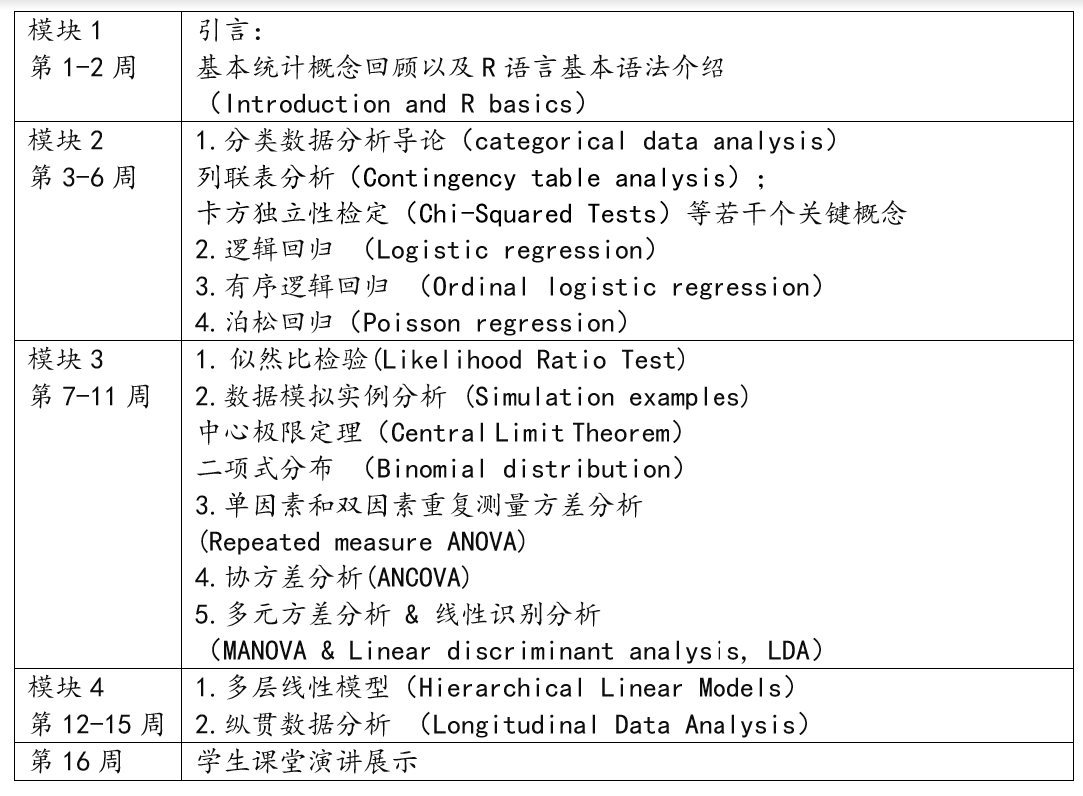
EDU7001 (7003) 高阶定量研究方法 课程内容
EDU6007 教育统计与计量 课程内容

EDU7003海报介绍
(上课时间:2026年春)
2025级学硕

频数分布热力图
汇报人:牛嘉仪
根据研究问题——“三轮课程迭代后,学生的AI素养是否提升”,本代码基于UNESCO AI CFT框架进行编码,分别统计五个维度(dimension 1–5)与三个能力层级(level 1–3)的频数。利用ggplot2绘制热力图,颜色越深代表频数越高,并在单元格内标注具体数值。通过热力图直观呈现三届学生的能力分布变化。

Mantel检验热力图
汇报人:赵紫涵
Mantel检验热力图是一种将Mantel检验结果与相关性热图相结合的可视化方法,主要用于探索两组多维变量之间的关联模式。它能够在一张图中同时回答两个问题。右侧变量之间如何相互关联?左侧每个分组变量与右侧每个变量是否存在显著的整体关联?这种整合避免了呈现大量表格的冗余。相比普通热图,它增加了外部变量与内部变量之间“距离模式”匹配度的检验信息,更能揭示“物以类聚”的深层规律,是探索复杂多维数据关系的有效工具。

箱线图、热力图、柱状图与结课爱心gif
汇报人:薛妍慧
设计以父母教养方式为研究主题,基于收集到的 PAS、PPC、PBC 三维度量表数据,依托R语言完成完整定量分析流程。通过数据导入、描述统计、相关分析与回归建模等方法,探究教养维度间的内在关联,主要运用箱线图、热力图和均值柱状图进行可视化展示,直观呈现分析结果,最后生成了可自行设置倒计时和文案的结课动态爱心。

绘制地图热力图
汇报人:芦镜羽
基于SCImago Institutions Rankings中工程学科下高等教育机构数据,统计西欧和东欧各国进入工程学科排名的高校数量,并结合GISCO 2024国家边界数据,在EPSG:3035欧洲等面积投影下绘制欧洲高校数量分布图。代码包括数据读取、边界下载、属性合并、地图裁切、颜色分级、国家名称标注,并最终导出PNG图片。

SEMA3家族基因
表达分布气泡图
汇报人:郭泽宇
该气泡图展示SEMA3家族基因(SEMA3A–SEMA3G)在多种肿瘤中的分布情况。横轴为基因,纵轴为癌种,气泡大小和颜色分别表示数值大小及其高低(蓝低红高)。结果表明,不同基因在各癌种中的表现存在显著差异,其中SEMA3F整体水平较高,提示其可能在多癌种中具有重要作用。

教育总经费比较云雨图
汇报人:王雪纯
基于2017年中国各省教育经费数据,依托 R 语言完成数据筛选、地区分组、缺失值清理与对数变换预处理,运用ggplot2结合ggdist绘图包绘制水平版云雨图,通过半小提琴分布、箱线统计量与抖动散点的组合可视化,直观呈现东中西部地区教育经费的分布形态与区域差异规律。

箱型图、边际效应森林图、趋势预测图
汇报人:王睿
基于某校博士生的行政数据,在完成 Stata 数据清洗的基础上,借助 R 语言中的 ggplot2等程序包,构建Logit 模型并绘制结果图,从而直观展示博士生国际流动的类型和时长对其学术职业选择的影响。箱线图可直观展示学部和性别对博士生学术职业选择的影响,边际效应森林图能清晰呈现各系数的显著程度及作用方向,趋势预测图则反映流动时长与类型的交互效应,这些结果为后续政策制定提供了实证依据。
2025级学博

分面时间序列政策趋势图、分组散点回归图、多模型回归系数比较图
汇报人:李兴悦
- 时间序列趋势图,通过折线和置信区间展示政策实施前后不同地区、不同学校类型的成绩变化,并用垂直线标记政策节点;
- 分组散点回归图,通过点、回归线和分面结构分析学习投入与成绩之间的关系,同时用点大小和标签增强信息表达;
- 回归系数比较图,将多个模型的系数和置信区间可视化,用于比较不同变量在不同模型中的影响大小及显著性。整体特点是将统计结果与可视化结合,不仅展示趋势和关系,还体现不确定性与模型差异,具有较强的解释性和比较性。
EDU7003海报展览

分组散点回归图—李兴悦

时间序列趋势图—李兴悦

多模型回归系数比较图—李兴悦

多维学生行为特征与学业心理表现的关联性分析-赵紫涵

预测概率图——王睿

预测概率图——王睿

边际效应森林图——王睿

箱型图——王睿

2017年中国中东西部各省教育总经费比较云雨图——王雪纯

SEMA3家族基因在多癌种中的表达分布气泡图——郭泽宇

箱线图——薛妍慧

热力图——薛妍慧

均值柱状图——薛妍慧

结课爱心——薛妍慧

第二轮课程学生AI素养分布——牛嘉仪

第一轮课程学生AI素养分布——牛嘉仪

第三轮课程学生AI素养分布——牛嘉仪

有国家名称工程教学高校分布热力图——芦镜羽

无国家名称工程教学高校分布热力图——芦镜羽
EDU7003海报介绍(待更新)

多变的3d瀑布图
汇报人:王章涵
我向大家分享的是多种类型的3d瀑布图。3d瀑布图可以显示出不同类型变量(分类变量)随时间/次数等的变化趋势。
(一)基础版3d瀑布图
基础版3d瀑布图只需要三个维度的数据,在教育中可以应用的情况包括:
(1)呈现一个班一学年n次考试的不同学科的成绩随时间的变化
(2)行为分析:呈现一个班一节课n分钟内不同课堂行为出现频率随时间的变化
(二)高阶版3d瀑布图
3d瀑布图还可以纳入四维数据,形成高阶版3d瀑布图,放在上述两个案例中,即:
(1)在呈现不同学科成绩随时间变化的同时体现该班成绩在年级的排名
(2)行为分析:在呈现不同行为频率随时间变化的同时体现行为代表的内容深度(eg.知识记忆or创新)
(三)交互式3d瀑布图
利用plotly、htmlwidgets包可以绘制交互式3d瀑布图并保存成html文件。交互式3d瀑布图支持3d立方体的缩放、旋转,通过光标移动显示数据等,便于更加直观(酷酷)地呈现数据。
(四)美化版3d瀑布图
个性化设置曲线颜色、填充面颜色,使图片更加美观!

冲积图&玫瑰图
汇报人:宁宁
我展示的是冲积图(两列、三列)以及南丁格尔玫瑰图,可以直观展示数据的层级流动情况以及分布情况。
(一)冲积图
冲积图作为多维度数据流动可视化工具,冲显示了各个实体(或节点)如何在代表多个组或时间段的阶段中一起或分开流动。在这些图中,河流的宽度显示了每个类别内的大小或比例,类似于支流如何连接形成更大的溪流,或河流如何分裂形成各种分支。在教育研究领域尤其适用于生源路径追踪、群体特征分析、政策效果评估、跨周期对比等。
我选择的数据是R语言的UCBAdmissions数据集,需要用到ggplot2、ggalluvial包。
1.双列冲积图:可以直观显示不同性别填报院系的流动情况。是否录取以数据条带形式用颜色区分。
2.三列冲积图:直观展示性别到院系、院系到是否录取的数据流动情况。
(二)南丁格尔玫瑰图
南丁格尔玫瑰图是一种通过半径和角度双维度展示数据关系的环形可视化工具,在教育领域可用于直观呈现学科成绩分布、区域教育资源投入差异或年度招生规模变化趋势。我展示的是UCB报名不同院系的学生数量分布情况。需要用到ggplot2包。
(三)彩蛋之坐标系玫瑰图
无数据,依靠数学计算和坐标系建立。
EDU7003海报展览

基础版3d瀑布图-王章涵

高阶版3d瀑布图-王章涵

美化版高阶3d瀑布图-王章涵

美化版交互式3d瀑布图-王章涵

双列冲积图-宁宁

三列冲积图-宁宁

南丁格尔玫瑰图-宁宁

坐标系玫瑰-宁宁
EDU6007海报介绍

词云
汇报人:刘妍
我的R语言分享主要包括1)词云图;2)数据拆分与合并。词云图是一种呈现高频关键词的可视化表达,适合用于文本数据的处理。词云图清晰呈现每个词汇的词频分布,通过色彩、图形的搭配,产生有冲击力地视觉效果。字体越大代表词汇出现频率越高。它在教育领域的应用比较广泛。比如,入学招生数据可视化或文献计量学中的关键词呈现等均可使用词云图。
此外,在数据处理方面,我分享了如何合并数据框、拆分合并列。不同文档的数据可以通过“合并数据框”连接,一个文档不同列的数据也可以通过 “拆分合并列” 的方式进行合并拆分。

雷达图 & 热力图
汇报人:沈思琦
我的R语言分享包括(1)热力图,体现数据的密度、分布以及变化,通过选择不同的颜色来对应不同的数据区间,将数据量大小转化成颜色差异,使我们快速了解数据量分布情况。
(2)雷达图,是一种表现多维( 4 维以上)数据的图表。它在同一坐标系内展示多指标的比较情况。我使用的例子是高校学科评估数据。通过雷达图,若干个高校在人才培养、师资队伍等维度上被比较。离圆心越远,代表该学校在该维度的表现越好。

forcats函数包 &
数据清理 &
因子水平可视化
汇报人:吴佳佳
我的R语言分享主要介绍forcats软件包。软件包自带的大型数据集是美国综合社会调查数据。首先,我用forcats函数对数据(比如缺失值)进行处理。数据处理是定量研究开展的必要环节,通常不呈现在论文汇报中,但却是每一个定量分析从业人员必经的环节,也是进行后续推论统计的必要阶段。其次,我关注了该数据集的人口统计学变量。以分类变量排序图为例,我们可以通过该图快速定位最大值和最小值。这种数据呈现方式使得一些特征更易于被观测。

山脉图 & 堆积条形图
汇报人:陈奕喆
我的R语言分享是(1)山脉图。该图用于观察一个连续变量在不同组别中的分布情况。比如,我使用的例子是研究国家级一流本科课程授课教师的课堂师生互动行为特征。随机抽取某一课堂,山脉图可以呈现教师在这一课堂互动行为持续时长的分布情况。(2)堆积条形图用于呈现不同连续变量在不同组别中的分布情况。在这个研究情境中,利用堆积条形图可呈现各学科教师实施多种课堂互动行为的持续时长,并进行学科间比较。如果进一步利用堆积条形图的变体—百分比堆积条形图,可以直观地看到各学科教师实施多种课堂互动行为的占比,进而总结其课堂互动模式。

相关性热图 & 流程图
汇报人:刘佳奇
我的R语言分享是(1)相关性热图,ggcorrplot包是基于ggplot2的扩展包,针对相关系数输出的结果进行可视化,同时可以计算相关性p-value,也可以实现选择颜色,文本标签,颜色标签,布局等操作。相关性热图在教育领域的应用,主要适合用于调查研究中的相关性分析。树状图则对于调查研究初步的数据探索有一定的帮助,可以直观展示出数据中不同组别数据的分布情况。
(2)流程图(vtree),主要用于探索数据以及制作流程图,做出的流程图可以直观的展示分类变量/连续变量的归属情况。

绘制残差 &
密度图 &
数据高亮
汇报人:牟丛菁
我的R语言分享主要包括绘制残差、密度图与数据高亮三个部分。这些工具在分析大量学生分数时,有重要作用。
(1)绘制残差
残差(Residual)是指实际观测值与估计值之间的差值,用以考察模型合理性及数据的可靠性。利用R语言中的ggpmisc安装包即可用一行代码将残差绘制出来。
(2)密度图
密度图(Density plot)是用一条连续的曲线表示的变量的分布,可以理解为直方图的“平滑版本”。ggplot2安装包即可绘制密度图。其中,既可以描述一个连续变量的分布情况;也可以描述一个连续变量在一个分类变量的不同类别下的分布情况,分组绘图。
EG:现将某高校大二、大三、大四学生的平均学分绩点(GPA)作为数据源:在密度图中,既可以只描述大二学生GPA的分布情况,绘制出一条曲线;也可以同时描述三个年级学生的GPA分布情况,用不同的颜色标识三条曲线与横轴间的范围。
(3)数据高亮
数据高亮(highlight)是指对某些数据散点或数据分布区域进行高亮显示,适用于散点图、密度图等多种分布图。使用R语言中的gghighlight安装包即可实现数据高亮。在散点图中,既可以高亮全部数据点中满足某项具体要求的点,也可以以一个分类变量的各个类别为划分依据,分别高亮各个类别中的全部数据点。
EG:现将某高校大二、大三、大四学生的大学英语六级成绩(CET-6)作为数据源:在散点图中,可以高亮CET-6成绩为448分的所有数据点,也可以分别高亮三个年级全部的CET-6成绩,不同的年级会以不同的颜色进行高亮。密度图同理。

豆荚图
汇报人:林芳竹
我的R语言分享是豆荚图(bean plot),形似豆荚,可以用R语言中的beanplot软件包绘制。豆荚图与箱线图的功能类似,均为显示一组数据的分布情况。但相对于箱线图来说,豆荚图可以更清楚地表达出箱线图隐藏的信息,能够区分均匀分布与双峰分布。并且,豆荚图可以将一个分类下亚组的分布情况在一个图中进行展现,更加直观清晰,有利于读者更快地捕捉到需要的信息。
我使用的例子:探究不同的课程教学模式对不同专业的医学院的学生共情能力的影响。先对某医学院的内科、儿科、护理学三个专业学生的共情能力进行测量,并用豆荚图呈现。之后,在实施两年的新型教学模式后,对同一批学生进行二次测量。将每一个专业的共情能力前后测的成绩在一张图中表现出来。用豆荚图进行数据展示,既能体现同一专业前后测的差异,又能表现不同专业整体水平的不同。

国际大型测评数据可视化
汇报人:王天琪
国际大型测评项目如PISA、PIAAC等备受瞩目,有助于全面评估学生等不同社会群体的学习现状和教育目标的达成情况,考察学生发展的影响因素,为教育政策的制定提供客观依据。通过ggplot2,可以更为丰富地实现数据可视化结果。如可以看到PISA(国际学生评估项目)中,不同国家/地区、不同性别作答对象的成绩分布情况(均值、最小值与最小值区间、差异差距情况)或PIAAC中,不同国家不同年龄段作答对象的成绩分布情况。在我使用的例子中,我将不同国家参与大型国际测验的人数放在同一标准下进行比较,展现不同年龄段的人数占比。同时,借助此代码,我们也可以将收集到的数据以更为直观的方式予以呈现,尤其是基于likert量表得来的数据。

环形柱状图 &
散点动态图
汇报人:张子清
我的R 语言分享是(1)环形柱状图,(2) 散点动态图。柱状图需要tidyverse包,其优点在于:当数据量较多时,依次排列会导致图非常长,而环形柱状图则可以将这些数据以环形来表示,节省空间,清晰直观。比如,当对比50个学生,每个学生在本学年的5次考试的平均数。可以事先在R中对这一数据进行排序,然后使用环形柱状图进行绘制,便可从小到大呈现,一目了然。
散点动态图需要加载ggplot2、gganimate、av包,其主要优势是在进行汇报展示时引起观众的关注和兴趣,着重关注数据的变化。在我使用的例子中,散点图的3个颜色代表3个不同地区,它们以动态方式呈现。

一行代码出回归表格 &
集合可视化神包UpSetR
汇报人:倪凯歌
首先向大家分享flextable包。在建立回归模型后,下一步就是将结果制作成表格,再进行汇报或者发表,但回归表格的制作有时比较烦人。现在我们使用flextable包可以一行代码就打出简洁又美丽的回归表格。我的第二个分享是可视化神包—UpSetR!说到集合数据可视化,我们可能会首先想到韦恩图,它可以用来直观表征不同集合之间的重叠关系。当集合数比较少的时候,绘制韦恩图可以一目了然,但当集合数比较多(比如 5 个以上)的时候那往往会看得眼花缭乱了,这时就可以用UpSetR来解决多集合数据关系的可视化。在教育研究领域中,UpSetR也有一定的应用潜力,如对一组关键变量进行研究时,不同的研究对象只具有其中一个或几个变量特征,此时用UpSetR就能比较清晰地对研究对象进行描述分析等。我在这里暂且使用软件包自带的大型数据集-movies。

聚类分析图
汇报人:宫瑞
我的R语言分享是关于聚类分析的可视化。k-means是聚类中最简单的,也是最常用的一种方法。在R 语言中,一般根据经验或者预判,确定k。k-means以k作为参数,把数据分为k个组,通过计算,将各个分组内的所有数据样本的均值作为该类的中心点,使得组内数据具有较高的相似度,而组间的相似度最低。在我使用的例子中,不同颜色代表不同的组。聚类分析可以作为一个单独的工具以发现数据库中包含的一些深层的信息,并且概括出每一类的特点。此外,聚类分析也可以作为其它分析算法的一个预处理步骤。

小提琴图 &
Rainclouds Plot
汇报人:王国耀
我的R语言分享是(1)小提琴图,(2)Rainclouds Plot。它们和传统的箱型图类似,但是它们可以提供更细致的信息。小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。raincloud plot由4部分组成,从上到下依次为:“云”:数据核密度,半边小提琴图(violin)表示;“伞”:boxplot;“雨”:云下面的数据点;“雷”:连接不同组均值的线。相比于bar plot,boxplot,violinplot等,raincloud plot可以更全面细致地描述数据并且可以在视觉上比较每个组的差异。
小提琴图 &
Rainclouds Plot
汇报人:王国耀
我的R语言分享是(1)小提琴图,(2)Rainclouds Plot。它们和传统的箱型图类似,但是它们可以提供更细致的信息。小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。raincloud plot由4部分组成,从上到下依次为:“云”:数据核密度,半边小提琴图(violin)表示;“伞”:boxplot;“雨”:云下面的数据点;“雷”:连接不同组均值的线。相比于bar plot,boxplot,violinplot等,raincloud plot可以更全面细致地描述数据并且可以在视觉上比较每个组的差异。
EDU6007 海报展览厅

词云--刘妍

热力图--沈思琦

雷达图--沈思琦

分类变量排序图--吴佳佳

分类变量的数据分布可视化--吴佳佳

美国综合社会调查数据概览--吴佳佳

山脉图 & 堆积条形图--陈奕喆

相关矩阵--刘佳奇

树状图1--刘佳奇

树状图2--刘佳奇

树状图3--刘佳奇

流程图--刘佳奇

绘制残差--牟丛菁

密度图--牟丛菁

数据高亮--牟丛菁

豆荚图--林芳竹

国际大型测评数据可视化--王天琪

国际大型测评数据可视化--王天琪

环形柱状图 --张子清

散点动态图1--张子清

散点动态图2--张子清

聚类分析图--宫瑞

Rainclouds Plot--王国耀

小提琴图--王国耀

一行代码出回归表格--倪凯歌

“高级韦恩图” -- 倪凯歌
EDU7001海报介绍(待更新)

Interactions 软件包探索
&调节效应
汇报人:罗沛君
探索了 Interactions 软件包:
1.回归与交互作用
2.调节变量与可视化
3.权重及可视化
4.Partial Effect Plot(偏效应图)
5.检验模型中的线性假设
6.Simple Slopes Analysis(简单斜率分析)
7.Johnson-Neyman intervals
8.3-way interaction
9.Categorical interaction(分类变量的交互)
10.调节效应-调节效应是指如果变量X与变量Y有关系,但是X与Y的关系受第三个变量W的影响,那么变量W就是调节变量,调节变量所起的效应就是调节效应。
一个小tip:如何找到你想要的包:
官网提供了一个Task Views:https://cran.r-project.org/web/views/,
通过它你可以了解R的主要功能。
EDU7001海报展览

J-N 3-way interaction-罗沛君

调节效应-罗沛君

分类变量的交互-罗沛君

班级合影
(2026年春
高阶定量和R语言)

班级合影
(2021级学硕)

班级合影
(2022级学硕)

班级合影
(2024年春
高阶定量和R语言)




















































































